Learning Batch Processing the Hard Way - Worklog
Hey everyone 👋,
Writing this worklog makes me feel nervous because it has made me realize how little I know about batch operations, vectorization, and parallel computation. This is what I learned while trying to figure out and build the preprocessing pipeline for my GSoC project.
One more thing: I started writing this worklog right when I felt the need to do so—right when I understood that I actually understand very little about how all this works. So the first part is basically me explaining all my doubts, questions, and where I went wrong before actually learning what was right. I'll be writing the first part in one go. However, I'll be writing the second part while learning about all this, so the second part might be a bit more elaborate.
All the code snippets and mentions of Jupyter notebook (or results of some cell runs) can be found in this notebook: https://colab.research.google.com/drive/1s5jSFwxhGAqIAHaCqpPUTkSeNSC8wbRu?usp=sharing
Oh also, sorry for not posting the weekly GSoC blog posts which I promised in the last blog. Working on the project itself is pretty time-consuming, however I'll try to catch up as soon as possible. Till then, enjoy this one!
How I Completely Misunderstood Batching - Part 1
First Stupid Attempt
Here's what happened: while trying to implement the preprocessing pipeline (ultimately the result would be converting any dataset into ChatML format, which will be used later for fine-tuning the model), I first implemented the entire pipeline by handling the dataset as a dictionary instead of as a Dataset or DatasetDict type (from the Hugging Face datasets library). Even though when trying to load the dataset from Hugging Face, it's a Dataset or DatasetDict by default, I was manually converting it to a Python dictionary. I honestly don't know why I did that. Maybe it was me trying to half vibe-code it and half manually code it, but honestly, it was ugly.
Since it was a dictionary of Python lists, to process the dataset and convert it into ChatML format, I used a manual loop (again, a stupid mistake).
While reviewing the code from a PR, Jet correctly pointed out that we could use the .map method instead of loops so that we could batch the processing.
Second Attempt
After this feedback, I realized that yes, we could do that, but we didn't really have the dataset as Dataset. So first I'd need to reimplement (not really, but make changes wherever necessary) to go from using a simple Python dictionary to handling the dataset as a dataset.
After successfully moving from dictionary to DatasetDict, it was time to use the map method to process the dataset.
I had this function that converts a single example to ChatML format:
def _convert_single_example(self, example: Dict, config: Dict[str, Any]) -> Dict:
"""
Convert a single example to ChatML format.
This method converts one example from the input format to ChatML format,
applying field mappings, templates, and ensuring proper message structure.
Designed to work with dataset.map() functionality.
Args:
example (Dict): The input example to convert
config (Dict[str, Any]): Configuration for the conversion, including:
- field_mappings (Dict): Maps input fields to ChatML roles with type and value:
- type: "column" or "template"
- value: column name or template string with {column} references
Returns:
Dict: The converted example in ChatML format with messages field, or empty dict if conversion fails
"""
try:
field_mappings = config.get("field_mappings", {})
messages = []
if "system_field" in field_mappings:
system_config = field_mappings["system_field"]
if system_config["type"] == "column":
if system_config["value"] in example:
system_message = str(example[system_config["value"]])
if system_message:
messages.append({"role": "system", "content": system_message})
else: # template
try:
template_vars = {key: str(value) for key, value in example.items()}
system_message = system_config["value"].format(**template_vars)
if system_message:
messages.append({"role": "system", "content": system_message})
except (KeyError, ValueError) as e:
logger.warning(f"System message template formatting failed: {e}")
user_content = self._extract_content(example, field_mappings, "user")
if user_content:
messages.append({"role": "user", "content": user_content})
assistant_content = self._extract_content(example, field_mappings, "assistant")
if assistant_content:
messages.append({"role": "assistant", "content": assistant_content})
# Check if we have valid user and assistant messages
has_user = any(msg["role"] == "user" for msg in messages)
has_assistant = any(msg["role"] == "assistant" for msg in messages)
if has_user and has_assistant:
return {"messages": messages}
else:
# Return empty dict for failed conversions to work with map()
return {}
except Exception as e:
logger.warning(f"Failed to convert example: {e}")
# Return empty dict for failed conversions to work with map()
return {}For your reference, the _extract_content function checks if the field mapping for the given role is column or template. If it's column, then it basically returns the specified column value. If it's template, then templating might include references to a column in this format: The answer is {answer}. This string is a template, where the value of {answer} should be replaced by the value of the answer column for that data point. So if the field mapping is template, the _extract_content function does all this and returns the final string after putting the value of the referenced columns.
I used the above function to map over the dataset:
transformed_dataset = dataset.map(
self._convert_single_example,
fn_kwargs={"config": config},
batched=False,
remove_columns=dataset[next(iter(dataset))].column_names,
)So when it came time to use batched processing, I started thinking about how I could write a function that would perform this operation in batches.
One thing to note is that I thought the function used would be the same (_convert_single_example) and the map method would automatically apply some sort of magic and make the entire computation fast because of using batched processing.
However, I soon realized that I'd need a different function—one that's able to handle batch examples. At this point, all I could think of was writing a wrapper function _convert_batch_examples that would basically loop over the batch and call the _convert_single_example function.
Now while thinking about it, I realized that it would actually be slower. Let's look at it using an example:
To start with, suppose I have 100 data points. Let's start with no batching. In this case, the map method will call the _convert_single_example function 100 times.
Now let's do batched=True with batches of 4 data points. That means the Hugging Face map method will have to call the _convert_batch_examples function 25 times. Each time the _convert_batch_examples function is called, it'll call the _convert_single_example function 4 times sequentially (because I'm using a loop). That makes a total of 100 calls to _convert_single_example. Not just that, but also 25 calls to _convert_batch_examples.
That means using batched processing would actually have more overhead and hence would be slower. With this thought, I wrote a comment on the same PR explaining why I think we shouldn't do batch processing.
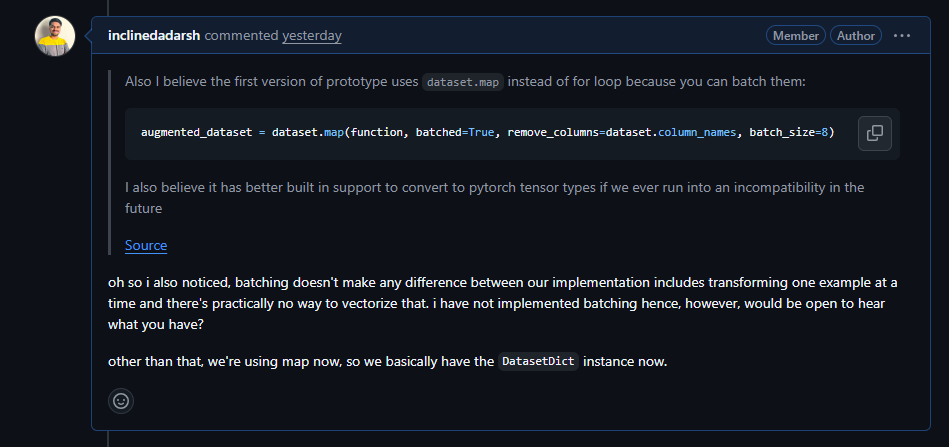
After this, Jet went ahead and actually did some testing and posted the results in the PR itself:
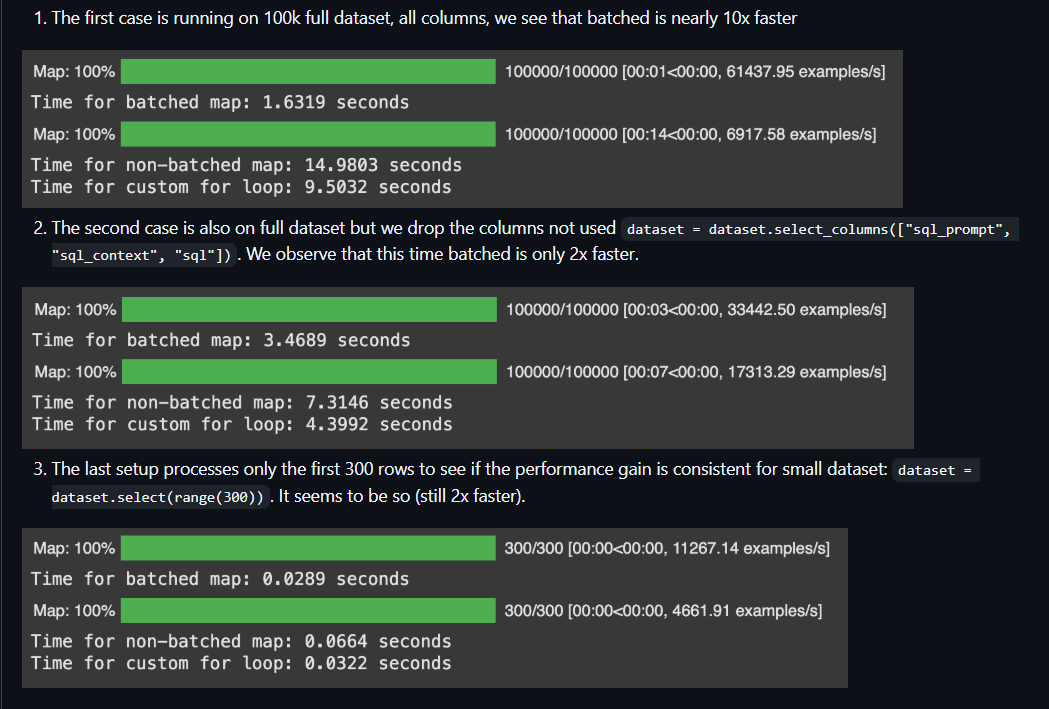
This made me rethink everything, and that's how I realized I understand nothing about how the map method and batching work in general.
Finding the Truth About Batching - Part 2
So now, accepting that I understand nothing, it's time to learn. I realized the best way to learn would be to go through the docs, talk to Claude (I prefer Claude over any other LLM while learning a new concept), and do some testing myself.
Fast forward: I talked a lot with Claude to understand a few concepts, and it's finally time to find insights from all that I learned, along with discovering what's the best approach for us.
A few questions to answer:
- Jet did the testing on GPU, but we'll be using CPU in production, so should we use
batched=Falseor not? - Do we need
num_proc? Though it absolutely speeds up the training, can we have that (based on our hardware)? - If
batched=Truedoesn't actually process the batches in parallel, then how does it speed up the process (as seen in Jet's results)? - One interesting thing to notice in the results Jet posted is that removing columns while batch processing takes more time, however removing columns while
batched=Falseor custom loop actually takes less time. Why is this? - What would be the effect of
remove_columns=dataset.column_nameson the processing? Is the trade-off of memory with time worth it?
To answer all these questions, it's time for me to run a Jupyter notebook and start doing some testing myself. Here's the Jupyter notebook in case you're interested: https://colab.research.google.com/drive/1s5jSFwxhGAqIAHaCqpPUTkSeNSC8wbRu?usp=sharing
If you find some mistakes in my method, do let me know by contacting me on X or sending a mail to dubeyadarshmain@gmail.com. I would really appreciate the help!
For this, I started by writing three functions (all can be found in the above-mentioned Jupyter notebook):
convert_to_chatml_single: It converts one single example to ChatML format.convert_to_chatml_batch_indirect: It converts a batch of examples to ChatML format by calling theconvert_to_chatml_singlefunction internally.convert_to_chatml_batch_direct: It converts a batch of examples to ChatML format, but does the computation itself without calling any other function internally.
Other than this, I'll be using the original synthetic text to SQL dataset which has 100K (or 1 million) rows. It's quite a big dataset and hence would be easy to differentiate between results of different cases. Even Jet used it in his initial testing, so I thought it would also help me compare my results with his.
1. Batching Actually Helps!
Test details: Ran all three functions (first one with batched=False and next two with batched=True) on CPU.
print("Default config results (CPU):")
start = time.perf_counter()
dataset.map(convert_to_chatml_single, batched=False)
end = time.perf_counter()
print(f"convert_to_chatml_single (batched=False): {end - start:.4f} seconds")
start = time.perf_counter()
dataset.map(convert_to_chatml_batch_indirect, batched=True)
end = time.perf_counter()
print(f"convert_to_chatml_batch_indirect (batched=True): {end - start:.4f} seconds")
start = time.perf_counter()
dataset.map(convert_to_chatml_batch_direct, batched=True)
end = time.perf_counter()
print(f"convert_to_chatml_batch_direct (batched=True): {end - start:.4f} seconds")The first test I did was comparing all three functions head-to-head with default configs (except the batched parameter for obvious reasons). The results contradicted my original thought process of how all this would internally work.
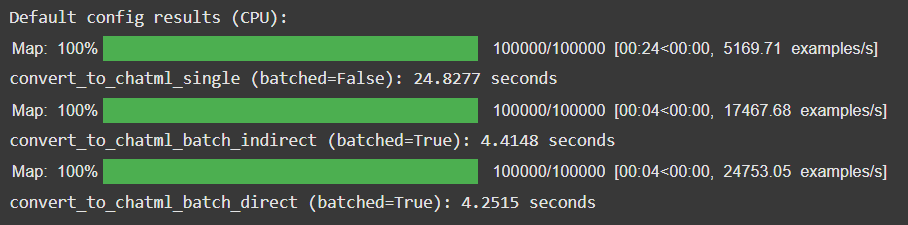
Some questions I had after this result:
- If batching does the same number of computations, then why is it 6 times faster? In fact,
convert_to_chatml_batch_indirectincludes more function calls than usingconvert_to_chatml_single, so why is this also 6 times faster? - I used the same dataset as Jet did, however his results were much better than mine. Why so? I don't think there will be a huge difference between our functions (though I'm not sure about it).
Well, talking to Claude and reading some articles, I realized that it's not parallelism that helps (btw, in case you're wondering if batched=True means running the batched operations in parallel, that's not true—everything still runs sequentially). It's neither the function call overhead that's making the difference (if it would make a difference, the results would have been opposite to what they are right now). It's actually the number of times the dataset has to be brought in during the process. In batching (by default batch_size is 1000), the dataset has to be interacted with fewer times than in the case of not batching it. Another reason is the number of times the Hugging Face datasets library has to interact with the Python function. In batching, that becomes less, so that helps as well.
For the second question, Jet mentioned using a T4 GPU for his testing, so that might be the difference. However, I learned (which was quite obvious as well) that the map method never actually runs on the GPU, but it includes string manipulation, and this fact weakens the reason of me using a CPU and Jet using a GPU. Hence we'll be testing this again later on GPU as well.
Now that we know batching helps, it's time to find a good batch size. I know this changes from dataset to dataset, but it'll still be interesting to see which batch size performs the best.
2. Let's Find the Sweet Spot in Batch Size
Test details: Ran the convert_to_chatml_direct function with different batch sizes.
print("Change in batch size with convert_to_chatml_batch_direct (CPU):")
for batch_size in [10, 100, 1000, 5000, 10000, 50000, 100000]:
start = time.perf_counter()
dataset.map(convert_to_chatml_batch_direct, batched=True, batch_size=batch_size)
end = time.perf_counter()
print(f"Batch size {batch_size}: {end - start:.4f} seconds")Here are the results:
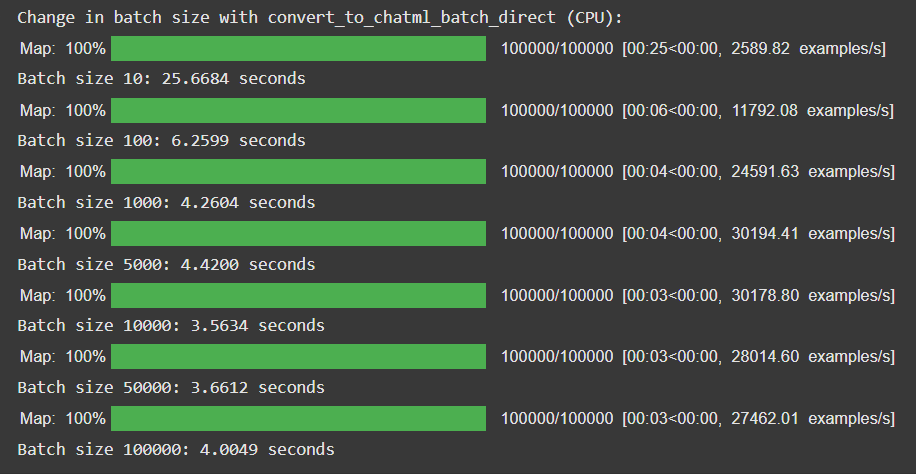
This result was quite expected. The time decreases to a point, and then starts increasing. The only reason that comes to my mind as to why the time starts increasing again is that the time it takes to interact with the database to get one big chunk gets bigger than the time it takes to interact with the database in two small chunks. In such cases, the time starts increasing again.
Cool, so I believe a batch size of 10,000 is the best. Though I'm sure if I dig deeper, I can make this result even better, but that's not the point.
For my application, where the dataset is chosen by the user, it'll be pretty hard to predict the best batch size. However, there's a good chance I can write a formula that calculates the batch size given the size of the dataset and performs better than having the default batch size of 1000. However, for now I won't be doing that. I'll be sticking with the default batch size of 1000 for the rest of the tests as well as my application for the sake of simplicity.
3. Removing Columns in the Result
Test details: Ran all three functions (first one with batched=False and next two with batched=True) with the remove_columns parameter on CPU.
print("Default config with remove_columns (CPU):")
start = time.perf_counter()
dataset.map(convert_to_chatml_single, batched=False, remove_columns=dataset.column_names)
end = time.perf_counter()
print(f"convert_to_chatml_single (batched=False): {end - start:.4f} seconds")
start = time.perf_counter()
dataset.map(convert_to_chatml_batch_indirect, batched=True, remove_columns=dataset.column_names)
end = time.perf_counter()
print(f"convert_to_chatml_batch_indirect (batched=True): {end - start:.4f} seconds")
start = time.perf_counter()
dataset.map(convert_to_chatml_batch_direct, batched=True, remove_columns=dataset.column_names)
end = time.perf_counter()
print(f"convert_to_chatml_batch_direct (batched=True): {end - start:.4f} seconds")This test was a very unintuitive test, as I couldn't think if this would make the process faster or slower. I was completely blank before running this test. Here are the results:
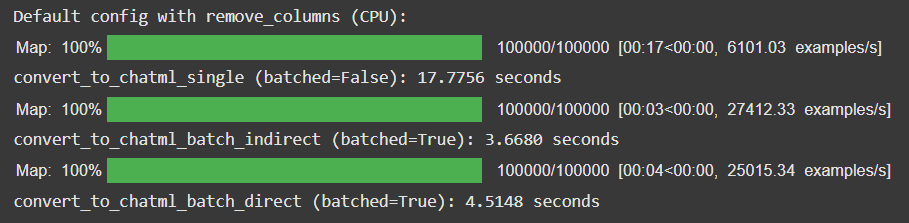
Well, this is good news, isn't it? We're saving the processed dataset on Google Cloud buckets. So removing unnecessary columns doesn't just save us time, but also processes the dataset faster. However, why does this happen?
My theory is that now the CPU has to keep track of fewer items. Now that we are removing the rest of the columns, the size becomes almost half of what it was. So the garbage collection overhead becomes less, which results in faster processing. Moreover, you might be wondering that this also includes one more operation—removing the columns—shouldn't that increase the time? The datasets library uses Apache Arrow data format internally, which is very fast in column-wise operations, so that reduces the effect that the additional operation would have originally had.
Again, all these are just theories, and there's a need to confirm these theories. However, I won't be doing that right now, because implementing the pipeline is more important than that.
4. Let's Test Parallelism (Or Let Parallelism Test Us)
Now before this test, I went ahead and researched the service we'll be using to deploy this pipeline, and I realized we're using the default configurations on a Google Cloud Container. By default, it spawns a container with only 1 vCPU. I don't think we'll be able to spawn containers in production with more vCPUs because it costs more (lol).
This means that we won't be able to run processes in parallel using the num_proc parameter. And even if we do, it'll just do context switching, which will increase overhead and ultimately increase the time. However, I thought it would be fun to see the results regardless. (Also, who knows, someone might just fund us and we'll be able to spawn better containers lol).
So for testing purposes, I searched how many CPUs Google Colab provides, and it's 2. So we'll be using num_proc=2.
Test details: Ran all three functions (first one with batched=False and next two with batched=True) with the num_proc=2 parameter on CPU.
print("Default config with num_proc=2 (CPU):")
start = time.perf_counter()
dataset.map(convert_to_chatml_single, batched=False, num_proc=2)
end = time.perf_counter()
print(f"convert_to_chatml_single (batched=False): {end - start:.4f} seconds")
start = time.perf_counter()
dataset.map(convert_to_chatml_batch_indirect, batched=True, num_proc=2)
end = time.perf_counter()
print(f"convert_to_chatml_batch_indirect (batched=True): {end - start:.4f} seconds")
start = time.perf_counter()
dataset.map(convert_to_chatml_batch_direct, batched=True, num_proc=2)
end = time.perf_counter()
print(f"convert_to_chatml_batch_direct (batched=True): {end - start:.4f} seconds")Okay yeah, it crashed. Turns out multiprocessing with num_proc > 1 is not reliably supported in Colab or even Jupyter notebooks in some cases. I could run this offline on my device using a Python file, but I wouldn't be doing that for now. However, feel free to go ahead and try doing this yourself locally. So sadly, no results for this one :(
Now go and read the title of this test again, and it should make sense now :)
5. Does GPU Make a Difference?
So now that we're done doing most necessary testing, let's run the first test again on GPU. Now theoretically, it shouldn't really matter, because the map method works on CPU only. However, just for the sake of it, I'll be running all the above code blocks on GPU.
Test details: Ran all three functions (first one with batched=False and next two with batched=True) on GPU.
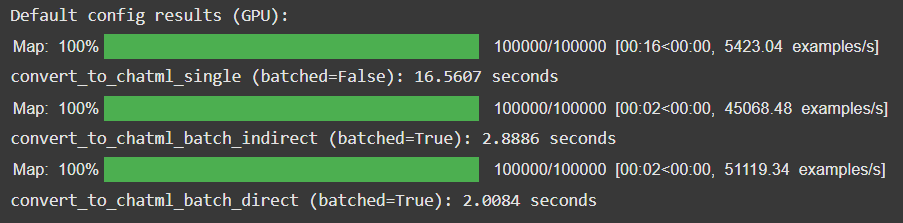
Wait, GPU really sped things up? That was totally opposite to what I thought. Moreover, the difference is now that direct batched processing is more than 8 times faster??? The only possible reason for this could be different CPUs while using CPU runtime and T4 GPU runtime. To test my theory, I ran the following code block in a different Colab notebook on GPU as well as CPU:
import psutil
import multiprocessing
import platform
import time
print("System Information:")
print(f"CPU logical cores: {multiprocessing.cpu_count()}")
print(f"CPU frequency: {psutil.cpu_freq()}")
print(f"RAM: {psutil.virtual_memory().total / (1024**3):.2f} GB")
print(f"CPU info: {platform.processor()}")
print("\nRunning simple loop now:")
start = time.perf_counter()
result = sum(x*x for x in range(1000000))
end = time.perf_counter()
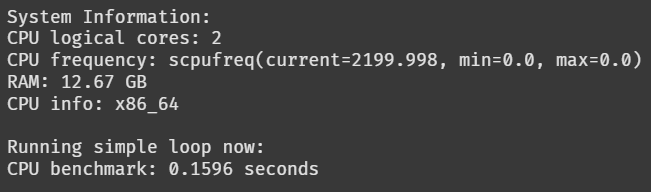
print(f"CPU benchmark: {end - start:.4f} seconds")Here's the result I got on the CPU runtime:
And here's the result I got on the T4 GPU runtime:
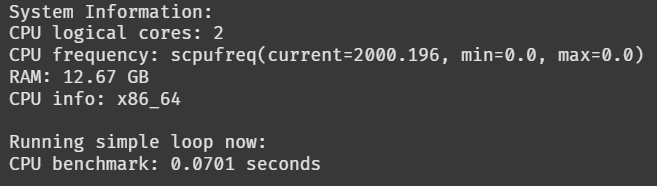
And this tells me that my theory is absolutely wrong. Though there's a difference between the benchmarking results, after I ran the same code block multiple times, I realized that in both cases the results are between 0.06 seconds to 0.15 seconds. So this difference in CPU benchmark doesn't really reveal anything, and neither does any other information.
Now my last theory regarding this significant increase in speed of the map method is that there are some internal structural differences between using a CPU runtime and a GPU runtime.
And at this point, I'm just lost between theories and assumptions, so it's time I go to sleep now.
Conclusion
Running the above tests and studying the docs definitely proves that I should be implementing the processing pipeline with the batched=True argument, and also with the remove_columns=dataset.column_names argument as well. Though this might not be a very big reveal, I got to learn a lot during this small research and fun testing (and I hope you learned something as well). Though there's a lot more to do and find right now, I believe this is enough to prove my initial intuition wrong (that batching won't help).
Also, kudos to Jet for doing the initial testing rather than just believing in postulates and theories. This made me run all these tests and verify the results myself (along with learning so much). If I were building this project alone, I would not do all this and just move on with my theories without verifying them. One lesson I learned from this is to always verify claims because that's the only way to truly understand a concept.
That's it for this time, folks. I hope you enjoyed reading this worklog. This was a very different blog post than my typical ones, but I enjoyed writing this one, so I'll definitely be writing more in the future.
If you like this blog, you can follow me on Twitter where I keep sharing such things.
Thanks for reading :)