GSoC Midterm: Project Overview, Updates and Future Plans

We're still deciding a name, and this is just a placeholder I have used. Btw, Jinko means artificial in Japanese.
Hello folks 👋
Long time no see! I hope you're doing fine, and so am I! GSoC midterm reviews were released a couple of days ago and I'm very happy to tell you all that I have passed this term with flying colors. This blog is going to be all about my project update, the mistakes I made during the first term and what my plans are. I have so much to write, especially because I haven't really updated about my project till now, so get yourself a cup of coffee and let's start!
Project updates
Woah! So while reading my previous blogs, I realized I haven't really shared a lot of information about my project. And the information I have on the GSoC page is pretty outdated. For those who haven't read my previous blog yet, I am collaborating on this project with Jet Chiang (and we already had his prototype to start with). So to start with, let me give you an overview of our project, and then we can move on to what my part is and all the updates related to it. You can find the source code at github.com/gemma-fine-tuning.
If you find some security vulnerabilities or something that can be improved, I would really appreciate you sending a quick message to my email or DMing me on Twitter or Discord @inclinedadarsh.
Overview
Goal
As the world advances more and more in language models, using them has become convenient for everyone. However, to date, everyone uses language models the way they are. Language models are trained to perform as a general assistant. However, imagine if you could have an assistant that can behave the way you want it to? That's where fine-tuning comes in. Though this sounds very exciting, the problem is that fine-tuning language models is still high-skill and knowledge-intensive work. Only people with in-depth knowledge about language models are able to fine-tune them, making the entry barrier pretty high.
Another thing to mention is that a lot of organizations are not able to utilize these language models (or so-called AI) in their workflow/for their users because of privacy and security implications. What's the solution? Self-hosting the model. However, not everyone can afford to self-host large language models (in fact almost no one can), and small language models don't really perform as needed, so the investment doesn't seem worth it.
The goal of my project is to eliminate the barrier of fine-tuning language models. We are creating a platform using which anyone could fine-tune any open source model without having to understand all the jargon related to it. Imagine being able to put a model on fine-tuning before sleeping, and waking up with the model tuned according to your preferences (or your dataset) and ready to use? That's what we're trying to achieve.
Woah, didn't really expect myself to write a whole goddamn pitch, but here we go!
Technical overview
This one's for all the tech nerds out there! So the project is divided into three main parts: frontend, backend services and devops/mlops. If I had to divide our project, then I believe the frontend would be around 20%, 20% would be ops and the remaining 60% would be the backend services.
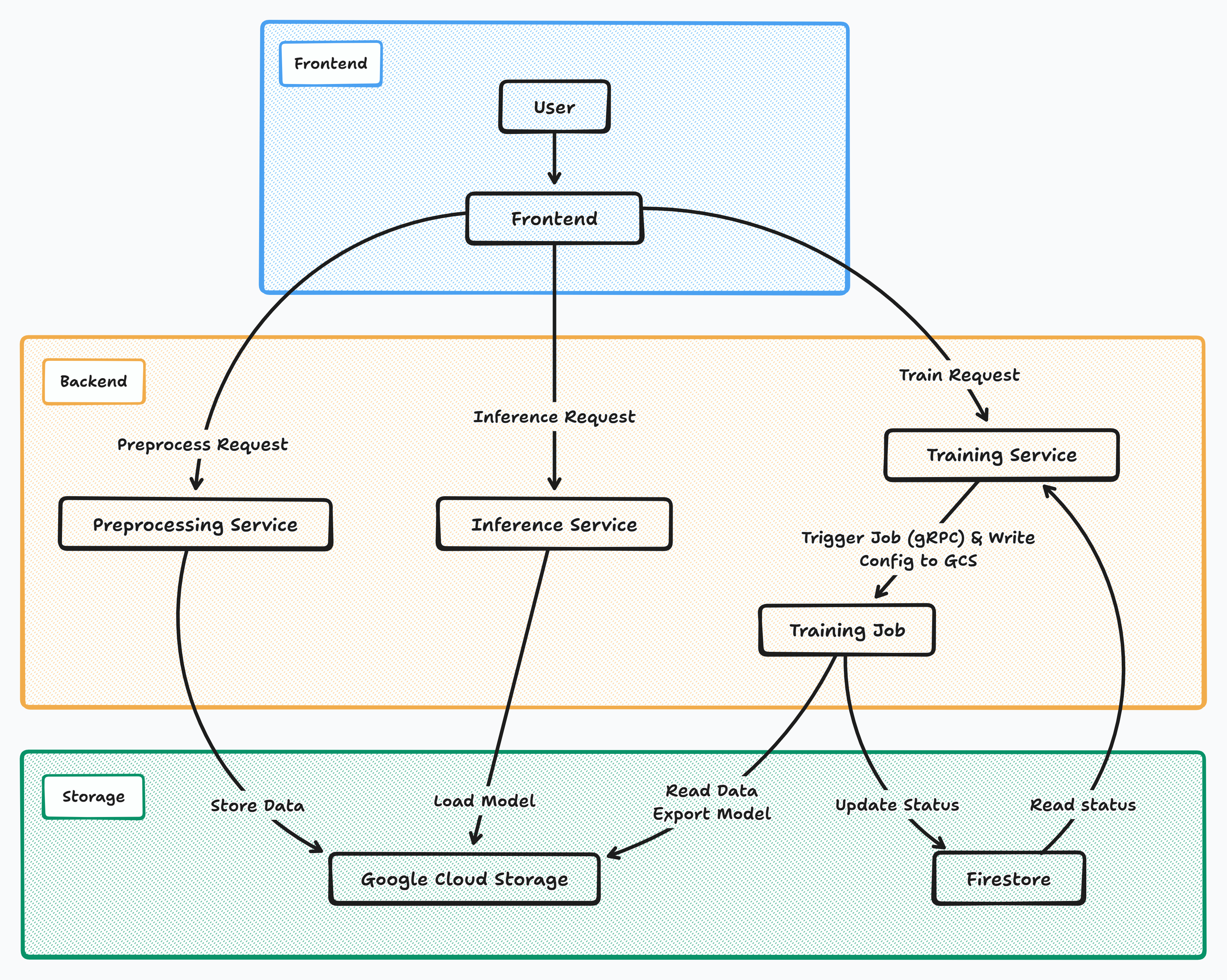
Backend services
Our backend has four services. All the services can be found at github.com/gemma-fine-tuning/services. These include: dataset (pre)processing service, training jobs orchestration service, the training jobs themselves and the inference service. All the services (except the training jobs) are FastAPI-based backend servers running on simple CPUs.
As the name suggests, the dataset preprocessing service simply preprocesses datasets. It has some features like uploading custom datasets (in formats like csv, parquet, json, etc.) The main job of this service is to process dataset into simple conversational format. It supports processing local as well as Hugging Face datasets. Dataset splitting using different splitting configs, choosing the size of the splits (using params like sample_size and test_size) and few more things are also supported. Moreover, one can also augment the dataset before processing using various methods (including a way to generate synthetic data using Gemini). The service stores all the processed datasets in a GCS bucket. The last thing this service does is retrieve information on all the processed datasets.
The training service is a pretty simple FastAPI service (again, running on CPU), which has the /train endpoint that accepts tons of config settings for model fine-tuning. It accepts multiple Gemma models' HF ID and the processed dataset ID to understand which model to train on which dataset. Moreover, we have also added support to fine-tune Unsloth's quantized Gemma models! Other than training, this endpoint also supports constant logging using Weights & Biases (well, this service doesn't do that part actually, I'll explain later) and also supports saving the fine-tuned model to the Hugging Face hub. Other than this, this service also retrieves fine-tuned models.
The jobs aren't really any kind of services. They're Python scripts that can be triggered to run on a GPU via the training service. These scripts actually fine-tune the model using all the information received. Moreover, we are using callbacks to log the status using wandb, and also update the Firestore database regarding the current status. Moreover, these scripts export the model to GCS at the end of training, and if needed then also publish the model on the Hugging Face hub.
At the end, the inference service can be used to run inference on any fine-tuned model. It simply loads the model from GCS and uses that for inference or batch inference operations.
MLOps
This is a part we have really been struggling with for two major reasons. The first reason being that ops is not our forte. The second reason is that we couldn't draw a line between working on backend and working on ops. Since this project is about fine-tuning models, we can't really develop this project with a local development setup, especially for the training part and inference part. We have been developing the backend right on the cloud (yes, we test in prod). But if I had to draw a line (a pretty blurry one) anyway, here's how I would divide this into three parts.
The first part is development and running the services. Operations was mostly figuring out why our training job crashed in the middle of training, why some jobs run while some just don't and more like this. Other than that, I guess figuring out how to trigger jobs using the training service and writing Dockerfiles took some effort.
The second part would be figuring out the storage. Well, this wasn't a lot to be honest, we figured out everything while developing the backend itself and didn't have to put much effort into this. The only part which took some problem-solving was developing a way that the preprocessing service could be used locally as well as with GCS whenever needed. After that, I don't think we struggled here a lot.
The last part is Infrastructure as Code (gotta use those big terms, you know!). Because we have so many services to set up, along with storage and other stuff, we (actually not me but Jet) realized that setting this all up again would be a headache. Moreover, we wanted this project to be as accessible as possible, but with so much setup it's the opposite. So he started working on Terraform and we're one our way to make sure that anyone can set up this project on their GCP account easily!
Frontend
Now, coming to the easiest (and well, for some reason also the hardest) part of the project, the frontend. You can find the source code at github.com/gemma-fine-tuning/frontend-next. We're using Next.js + TypeScript to develop a dashboard that could tie everything together, and provide users a friendly interface to process datasets and fine-tune models. Here's a sneak peek (well not really, because the entire project is open source 👀)
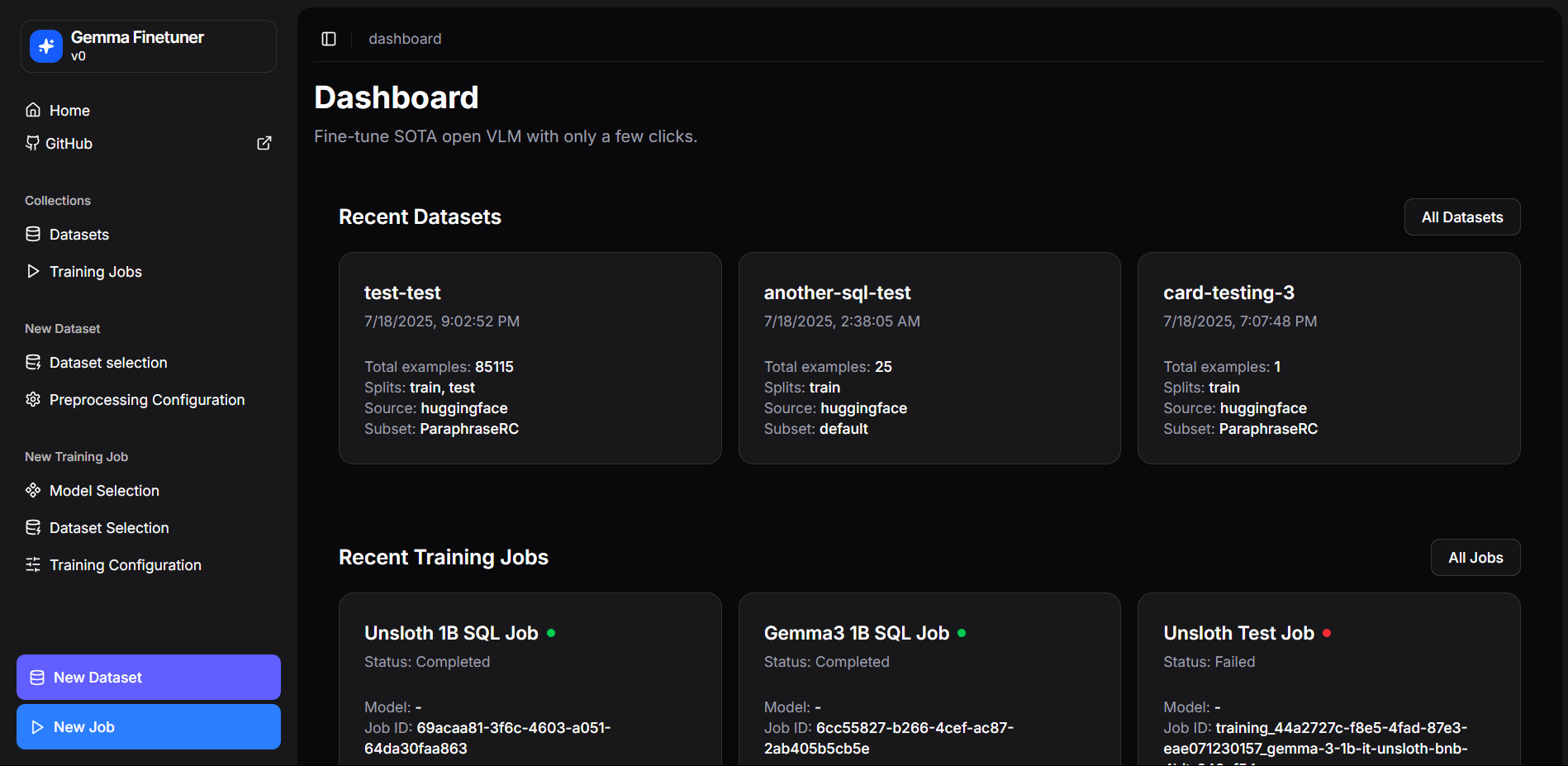
We have logically divided the entire dashboard into two parts, datasets and jobs. People can independently upload and process datasets and fine-tune models on those datasets. If they had been part of a single pipeline, then every time the user had to fine-tune a model, they would have to process a dataset. However, now people can process a dataset once, and fine-tune multiple models (or the same model with different training configs) on the same dataset they processed once.
My part
Cool, now that y'all know quite a lot about the project, I guess we're good to move on to my contribution to the project.
I primarily worked on the preprocessing service. Figuring out a way to run the same service with local storage and GCS was one of the problems I solved and would like to highlight. Being able to fine-tune local datasets as well as Hugging Face datasets was also quite a challenge for me, considering different processing configs. Other than that, most of the time went into making sure it's scalable, because we already had plans for GRPO and fine-tuning multi-modal models.
Other than this service, I also worked on setting up the frontend project with the dashboard and all the components that can be further used in the project. On the config part, since I worked on the preprocessing service, on the frontend as well I worked on the data preprocessing part.
To be honest, I did work quite a lot, but while writing this blog I am not really able to figure out what to write. Imposter syndrome? Maybe.
As this term ended on the 18th of July, here's the awesome review my mentor has shared with me!

Mistakes
Though the first term went amazing, I am able to easily point out a few mistakes I made which I would like to fix. Fortunately these mistakes weren't big enough to cost me extra time to achieve the first term goals, but aren't small enough to ignore either.
The biggest mistake would be not creating enough PRs. I started a PR on the backend to reorganize the preprocessing service, but ended up implementing the whole freaking service in that PR only. This might not seem like a really big mistake, but doing this makes it harder for Jet or my mentor to navigate my changes. Another mistake would be not creating enough issues on our repository. I love how Jet creates an issue before raising a PR for it. This small habit of his keeps me updated on what's coming up in the following days, so I could provide suggestions if I have any or plan my work accordingly.
I wanted to write a blog each week, but I guess that's not really possible, especially with a project of this scale. I should have understood this earlier. The pressure of writing a blog each week made me very lazy about writing blogs, ultimately resulting in only one blog (that too not really a blog, but a worklog) for the entire term!
I'll hopefully not make the same mistakes in this term. Moreover, I'll try to keep you folks updated via blogs, maybe two blogs each month? Let's see.
Plans for the next term
Okay, enough of the previous term. It was awesome, but gotta make sure the next term is 2x better than the previous term. We have a lot to learn and achieve.
We have many things planned, so much so that we never run out of things to do. At this point it's about prioritizing what needs to be done. Here are a few things on our list.
-
Multi-modal fine-tuning. Jet's already working on this and we'll hopefully be done with it in a week or two.
-
GRPO-based fine-tuning support. This is one thing I'm very much looking forward to. We haven't started work on this yet, but we'll be doing this soon!
-
Letting users export fine-tuned models. Though it won't be that hard to implement, it'll be one of the most useful features of our application. It'll have options to export models in GGUF and other formats.
-
Different types of dataset processing and model fine-tuning. Currently we're only able to process structured datasets. We need to add support such that users can simply put in huge PDFs as input and enable full fine-tuning on those datasets.
-
Project deployment. Maybe the hardest part to work on. We need to deploy the project so that people can actually use it. We're still not able to figure out how we're going to bear the GPU charges for letting people fine-tune models on our GCP account.
-
Guide. Yes, we'll be writing guides for people who don't know fine-tuning at all. The goal is that people could read these guides (which will not have any technical jargon at all) and fine-tune models according to their needs easily.
Obviously, this isn't an exhaustive list and there's a lot more to work on, these are just a few things that are on top of my mind right now.
Out of all the work that I mentioned above, I'm really interested in figuring out the GRPO support and adding different fine-tuning types. I guess project deployment is a place where we both will learn a ton! Other than that, everything else won't be less exciting either. Hoping to write more blogs and worklogs in this term!
Conclusion
That's all about the previous term. I hope now you understand my project at least a bit more and understand what problem we're trying to solve, and how we're trying to solve it. As you might be able to guess, we both are pretty passionate about this project, and are actively looking for feedback. If you have any questions or suggestions, feel free to email me at dubeyadarshmain@gmail.com and I'd love to connect with you over a quick call if needed.
If you enjoyed reading this blog, you can follow me on Twitter where I post updates about the project and other stuff I'm working on.
Thanks for reading 😊