The Small Language Model Revolution You're Probably Missing
Hey everyone 👋,
I hope you all are doing fine. This blog is going to be a short one, and definitely one different from my general blogs. I have been really interested in releases of small language models, however, I don't see enough people talking about them. This blog will be about the latest developments in this domain, why I'm excited about it and what it means for you.
Let's get started!
Before I begin, if anyone thinks that this blog is a promotion for Google DeepMind or MetaAI, then feel free to skip this blog 😉
Latest developments
So around a week ago Google DeepMind released Gemma 3 270M. I have been very excited about the release of such a small model, given the performance it produces. Looking at the benchmarks, it performs almost equally to Llama 3.2 1B. Not only this, it performs better than Qwen 2.5 0.5B Instruct model, which is almost double the size of Gemma 3 270M.
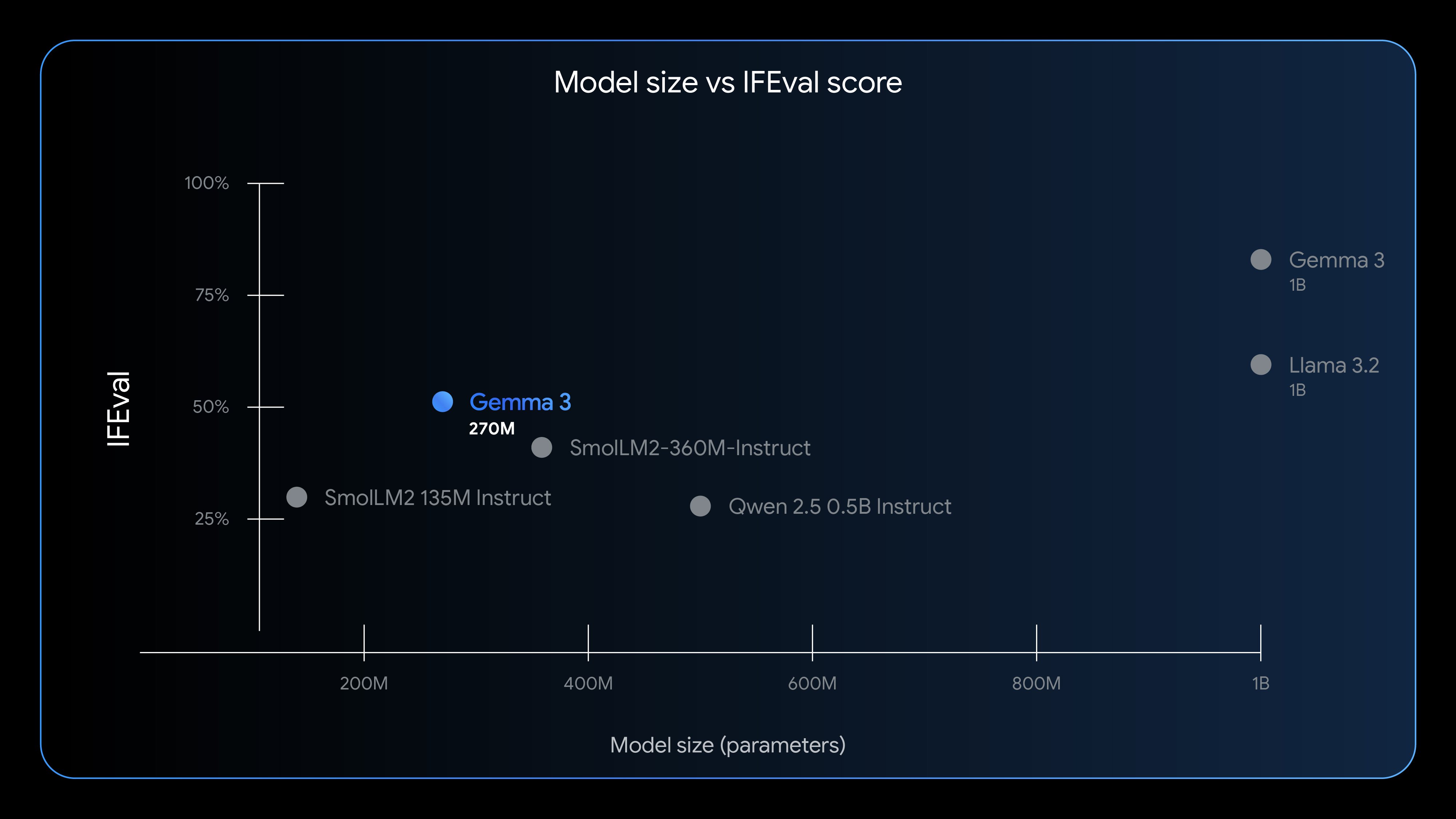
One sad thing about this release is that they haven't released any research paper or any more technical details about the model. During the release of Gemma 3n, they did release an official documentation which discusses the technical details about the release. Having more such technical details definitely helps, especially if it's an open weights model. But at the end of the day, this is definitely a very exciting release.
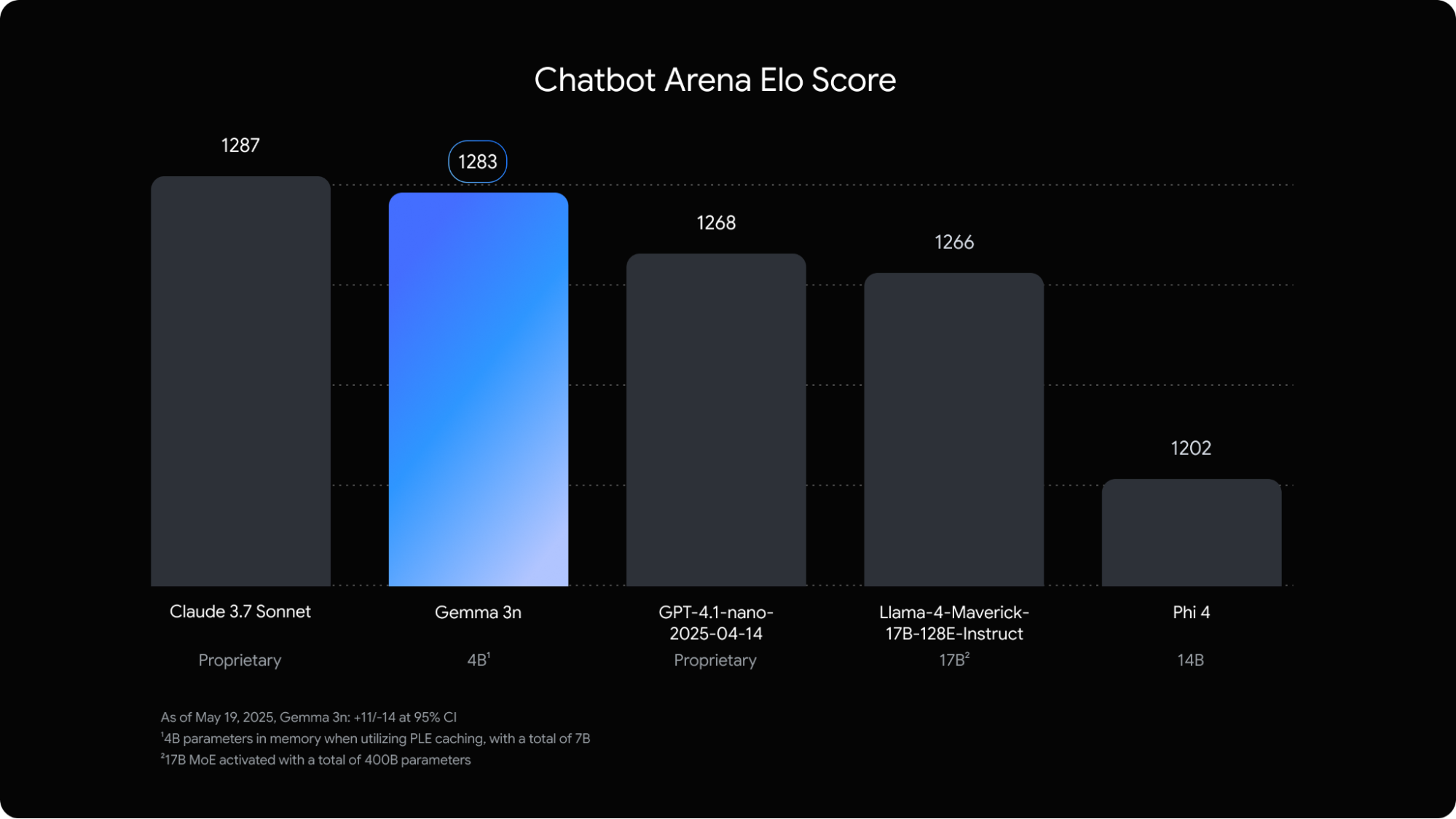
Well, we can't miss talking about Gemma 3n. Though not a small model, it definitely isn't too big either. Gemma 3n comes at 4B parameters and performs on par with Claude Sonnet 3.7. Definitely once I am a little less GPU poor, I'll be trying it out! Now back to talking about small models.
Meta released the MobileLLM (also available on Hugging Face) paper on 23rd Feb, 2024 (yeah, I know that's a long time ago) but finally released the models on 6th of May! These models start from 125M and go up to 1.5B parameters. Not just this, these models also have quantized versions.

| Model | arc_easy | arc_challenge | boolq | piqa | siqa | hellaswag | obqa | winogrande | avg. |
|---|---|---|---|---|---|---|---|---|---|
| OPT-125M | 41.3 | 25.2 | 57.5 | 62.0 | 41.9 | 31.1 | 31.2 | 50.8 | 42.6 |
| GPT-neo-125M | 40.7 | 24.8 | 61.3 | 62.5 | 41.9 | 29.7 | 31.6 | 50.7 | 42.9 |
| Pythia-160M | 40.0 | 25.3 | 59.5 | 62.0 | 41.5 | 29.9 | 31.2 | 50.9 | 42.5 |
| MobileLLM-125M | 43.9 | 27.1 | 60.2 | 65.3 | 42.4 | 38.9 | 39.5 | 53.1 | 46.3 |
| MobileLLM-LS-125M | 45.8 | 28.7 | 60.4 | 65.7 | 42.9 | 39.5 | 41.1 | 52.1 | 47.0 |
Though these models don't seem to be performing extraordinarily, the size at which they are built is definitely work that deserves appreciation.
So yeah, that was it for the latest developments in small language models. There have been a lot of releases, but these are the ones I have my eyes on. Now you might be wondering, why am I talking so much about small language models? Well, let's talk about that now.
Why am I excited?
I am the kind of person who loves to experiment with things. More than that, I'm the kind of person who actually believes that AI agents can do a lot of our work, but there aren't enough people working on it. Imagine going to a grocery store just to find AI managing the shop, that would be pretty interesting, right? Well, Anthropic ran a similar experiment called Project Vend. They let Claude manage an automated store in their office as a small business for a month. The experiment was not a simulation, but reality. Claude was allowed to email sellers, purchase stuff and decide what to buy and when to buy. It was in collaboration with Andon Labs and they actually released a research paper regarding this.
Btw, Andon Labs has a very cool leaderboard on their website, which ranks all the models by the profit they made by managing a virtual vending machine.
I find such experiments very cool, and have always wanted to conduct similar experiments locally. However, the biggest issue was always the capacity to run such models on my machine locally. Getting subscriptions (and API keys) to different LLM models is pretty costly, so that wasn't an option either. However, Gemma 3 270M changes that. With a model that small performing on par with Llama 3.2 1B, now I can run multiple instances of the model locally, test out different things, do some fun experimentations and enjoy myself!
Now someone with a pretty basic laptop can run a simulation of Project Vend, or just create something of their imagination. Imagine being able to write scripts and see AI agents doing some pretty crazy stuff. One such idea that recently came to my mind was making AI agents play some Crime RPG game, where the agents have to lie, form aliases, betray and do whatever they need to, to win the game. While researching about it, I found two such projects. One was a research paper called Time to Talk: LLM Agents for Asynchronous Group Communication in Mafia Games where the authors build a system that lets LLMs have a group chat. The other one is AI Plays Mafia in which the creator used a system similar to the one in the previously mentioned paper, and made AI agents play a variant of the game Mafia.
What I want to do is pretty similar to this, however there's still a lot of novelty to it. In the experiment I want to do, there should be a voting system, private chats which a bot can initiate and much more. I'll talk about it later, however to start with, if I'm able to replicate the 'AI Plays Mafia' game, that'll be a pretty impressive thing too! And just like me, you can also run such experiments with the help of these small language models.
Moreover, it's not just about doing small experiments, but rather building something useful. Even with the rise of such amazing LLMs, we see very few companies using them for their RAG and similar systems. The main reason is that they can't send their conversations to foreign systems. Well, you might be wondering then why don't they just self-host models, there are some pretty good open weights models available nowadays. The thing is, hosting models is a very expensive investment, which most companies are not able to make.
But now with the release of such small models, companies can fine-tune these models on their own data. While these models don't perform as well as bigger models on general tasks, when fine-tuned for one specific task, they can match the performance of much larger models for that particular use case. And that's all most companies need anyway. They don't require general intelligence, just good performance on their specific problem. These small models are comparatively very cheap to fine-tune and host, so the release of these models doesn't only affect us experimenters, but also has huge implications for large corporations.
I feel the pioneers of next gen AI models will be people like us, trying to do experiments with limited knowledge and resources. I feel we should be the people making noise about such releases, but we aren't. Maybe because we're too lost looking at those huge giants releasing new frontier models every month? Well, at least not me. I did my part by writing this blog and will keep doing so, by trying to play around with such cool ideas.
I hope you all got something out of this blog. This was definitely not like one of my usual blogs. If you liked this blog, then do let me know by texting me on X or just emailing me, that would make my day 😄. If you enjoyed reading this blog, you can follow me on X (Twitter) where I post about the projects I'm working on.
Thanks for reading 😊